10 Netzwerkbewertungen zur Ausfallprävention
NetBrain bietet eine Bibliothek mit gängigen Unternehmensnetzwerkbewertungen als Grundlage. Dank der No-Code-Plattform können Sie diese Vorlagen an Ihre individuelle Umgebung anpassen und erweitern. Ergebnisse lassen sich über widgetbasierte Übersichts-Dashboards einfach visualisieren und teilen, sodass Ihr Team Echtzeit-Netzwerkeinblicke erhält.
Hier sind die wichtigsten Netzwerkausfallbewertungen, die NetBrain Griffe in Minuten.
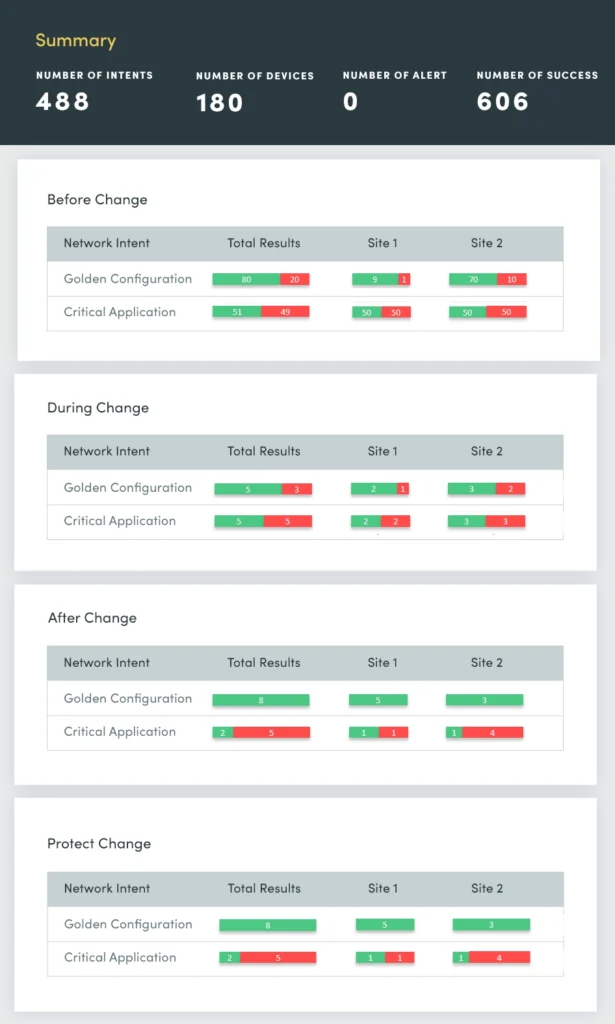
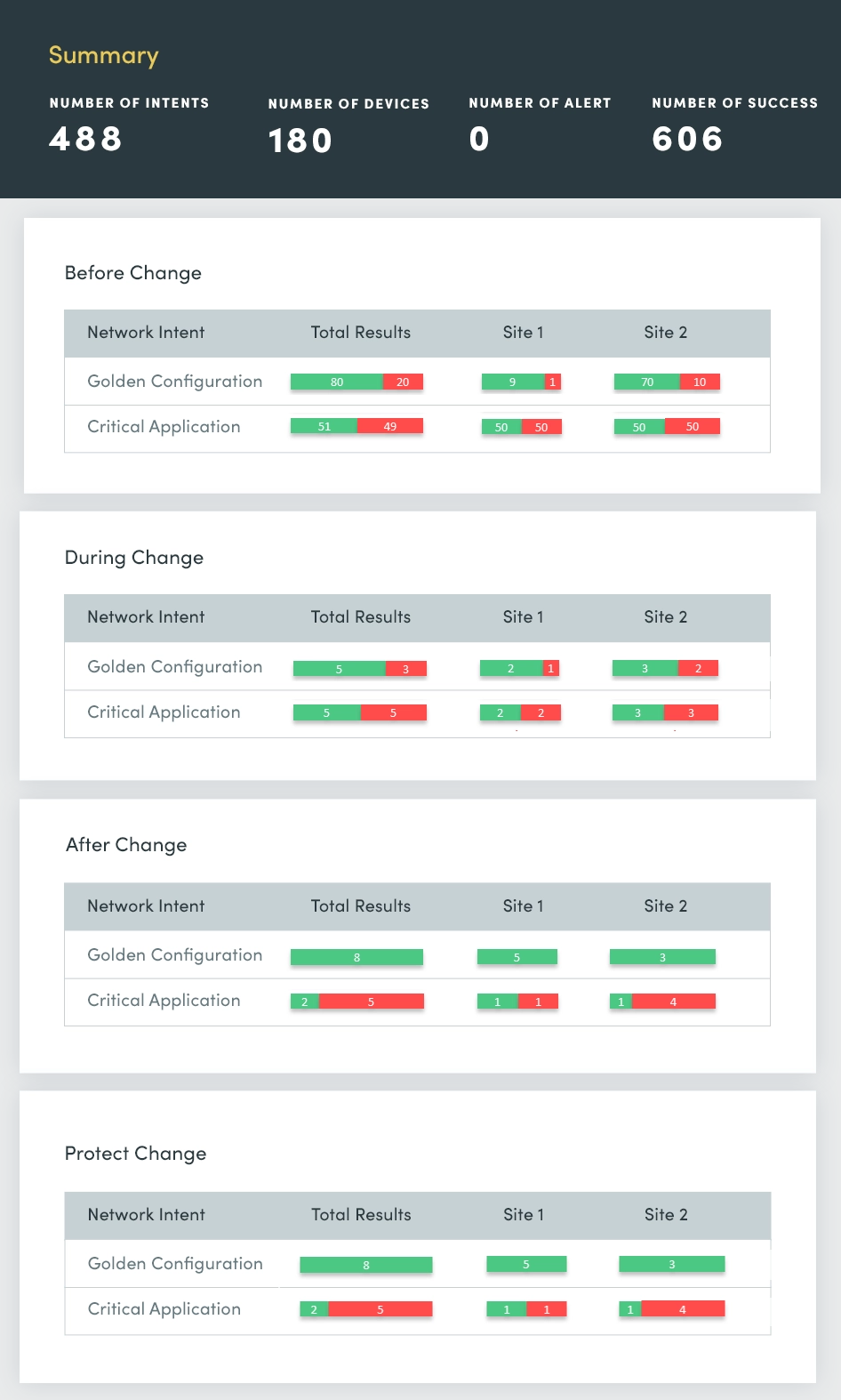
1. Änderungsbewertung
Zu Beginn jeder Woche gibt es Berichte über Netzwerkausfälle. Das wirft die Frage auf: Was hat sich am Wochenende geändert und wo sind diese Änderungen aufgetreten? Sie müssen diese Netzwerkänderungen schneller erkennen und feststellen, ob sie einen gemeinsamen Ursprung haben. So können Sie schnell reagieren und die Probleme beheben, um die Netzwerkstabilität zu gewährleisten und Störungen zu minimieren.
Mit einem Change Assessment bewerten und fassen Sie kontinuierlich Folgendes zusammen:
- Geräteergebnisse von device group
- ACL-Konfigurationsänderungen
- Routing-Konfigurationsänderungen
- Konfigurationsänderungen wechseln
- Änderungen der Failover-Konfiguration
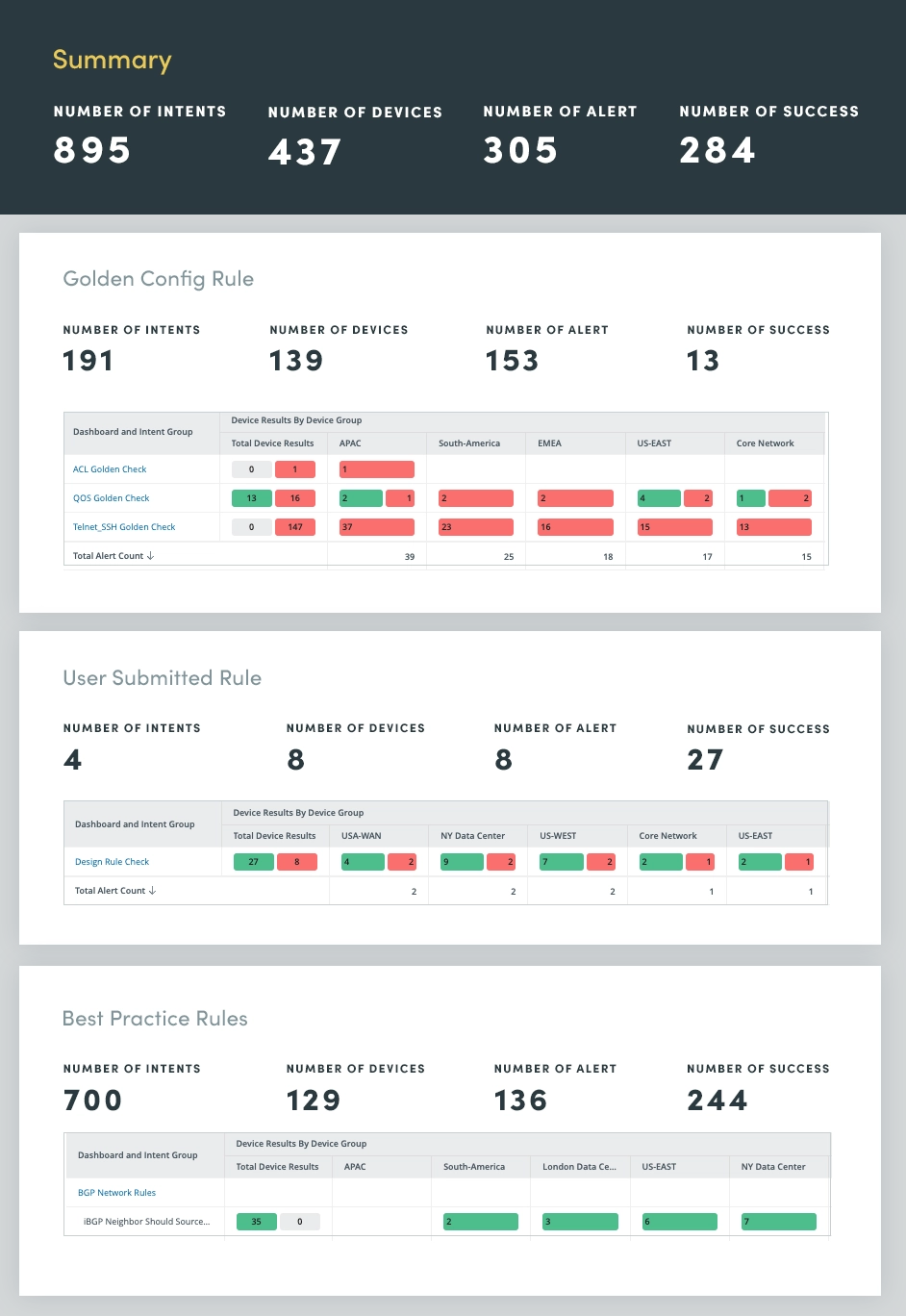
2. Anti-Drift-Bewertung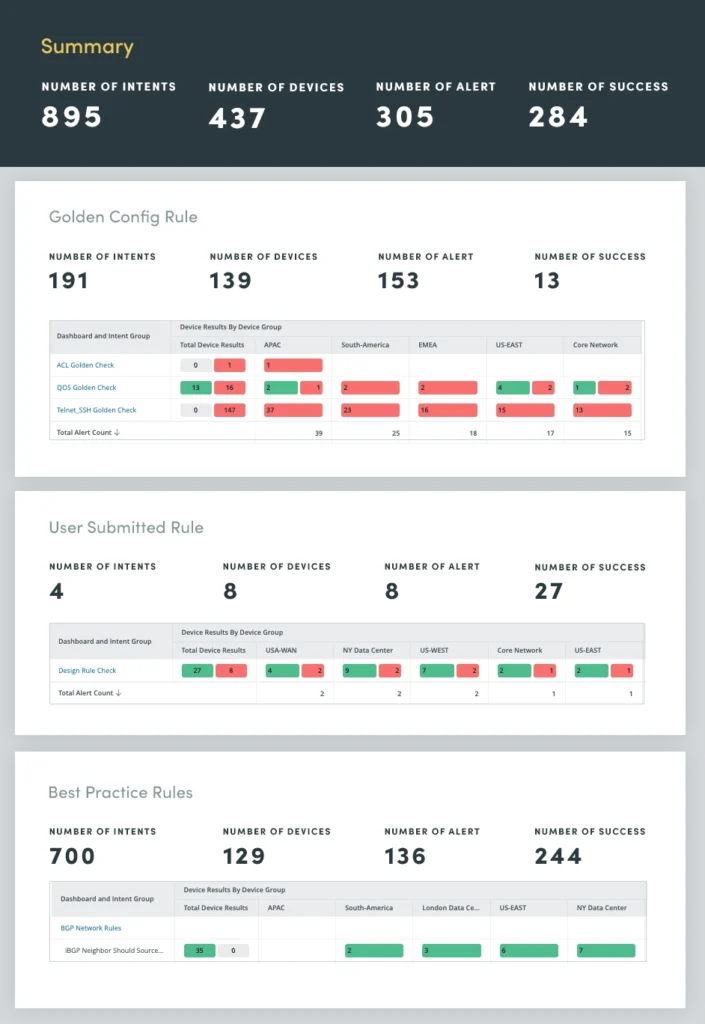
Menschliche Fehler, oft aufgrund manueller Netzwerkänderungen, sind eine der Hauptursachen für Netzwerkausfälle. Nutzen Sie daher eine Netzwerk-Anti-Drift-Bewertung, um Abweichungen von etablierten Konfigurationsregeln und Best Practices zu identifizieren. Durch die Automatisierung der Durchsetzung dieser Regeln können Sie die Häufigkeit menschlicher Fehler deutlich reduzieren und die Netzwerkstabilität gewährleisten.
Die Anti-Drift-Bewertung umfasst drei Regelkategorien:
- Design- und Best-Practice-Regeln: Diese Regeln beschreiben branchenweite Best Practices für Netzwerkkonfigurationen und stellen sicher, dass das Netzwerk anerkannten Standards und Richtlinien entspricht.
- Goldene Konfigurationsregeln: Diese Regeln stellen die spezifischen Konfigurationsstandards der Organisation dar und schreiben die Einhaltung interner Richtlinien und Verfahren vor.
- Vom Benutzer übermittelte Designregeln: Diese Regeln decken das Fachwissen von Netzwerkarchitekten und -ingenieuren ab und umfassen Designprinzipien und Richtlinien, die auf die einzigartige Netzwerktopologie und die Anforderungen des Unternehmens zugeschnitten sind.
Durch die Automatisierung der Durchsetzung dieser Regeln können Sie Konfigurationsdrift wirksam verhindern und das Risiko menschlicher Fehler minimieren. Dieser proaktive Ansatz erhöht nicht nur die Netzwerkstabilität, sondern verbessert auch die allgemeine Netzwerkleistung und -sicherheit.
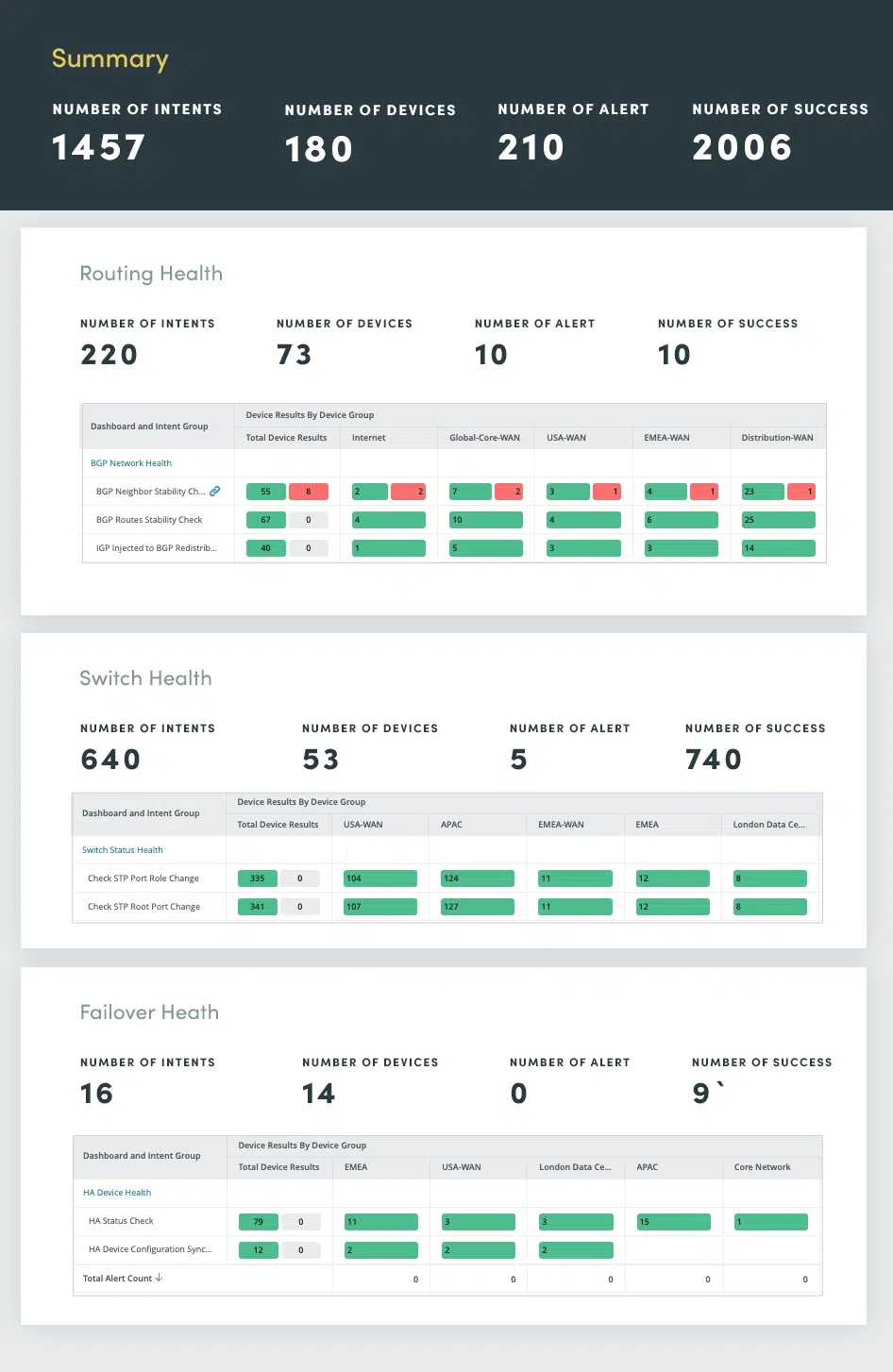
3. Bewertung der Netzwerkgesundheit
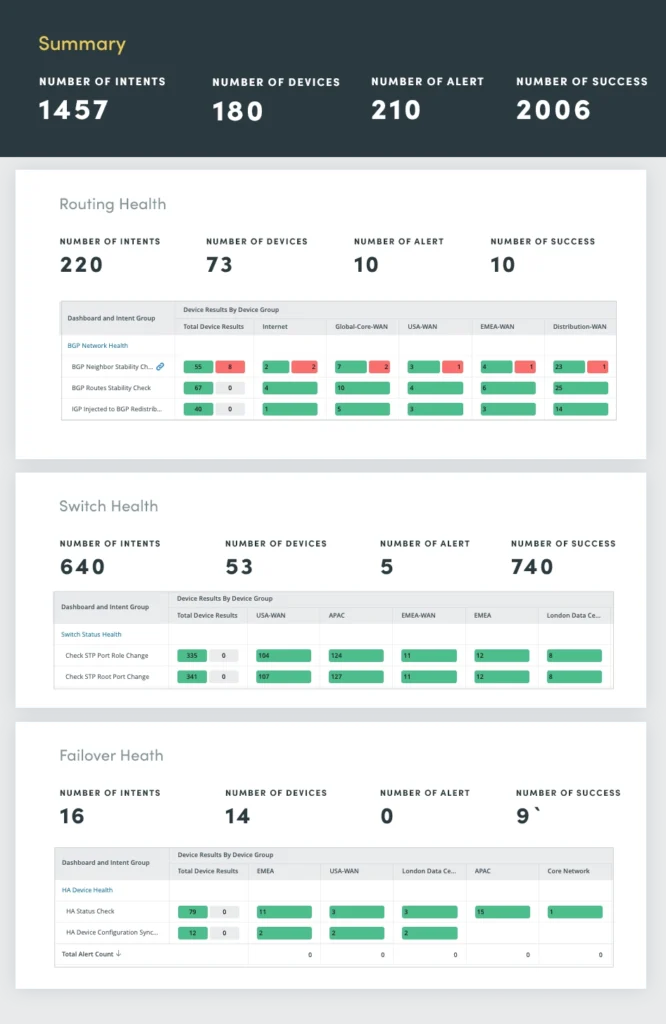
Eine ausgefeilte Netzwerkredundanz sorgt für zuverlässige und leistungsstarke Konnektivität. Wenn diese Funktionen jedoch nicht ordnungsgemäß überwacht und gewartet werden, können sie zu potenziellen Problemen führen. Die kontinuierliche Bewertung des Netzwerkzustands spielt eine entscheidende Rolle bei der Identifizierung und Behebung potenzieller Probleme, bevor sie zu größeren Ausfällen führen.
Die Bewertung des Netzwerkzustands umfasst eine umfassende Auswertung von Routing-, Switching-, Failover-, VPN-, WLAN- und Fehlerprotokollen.
Durch die kontinuierliche Bewertung dieser kritischen Netzwerkkomponenten können Sie potenzielle Probleme proaktiv identifizieren und lösen und so eine optimale Netzwerkleistung, Verfügbarkeit und Sicherheit gewährleisten.
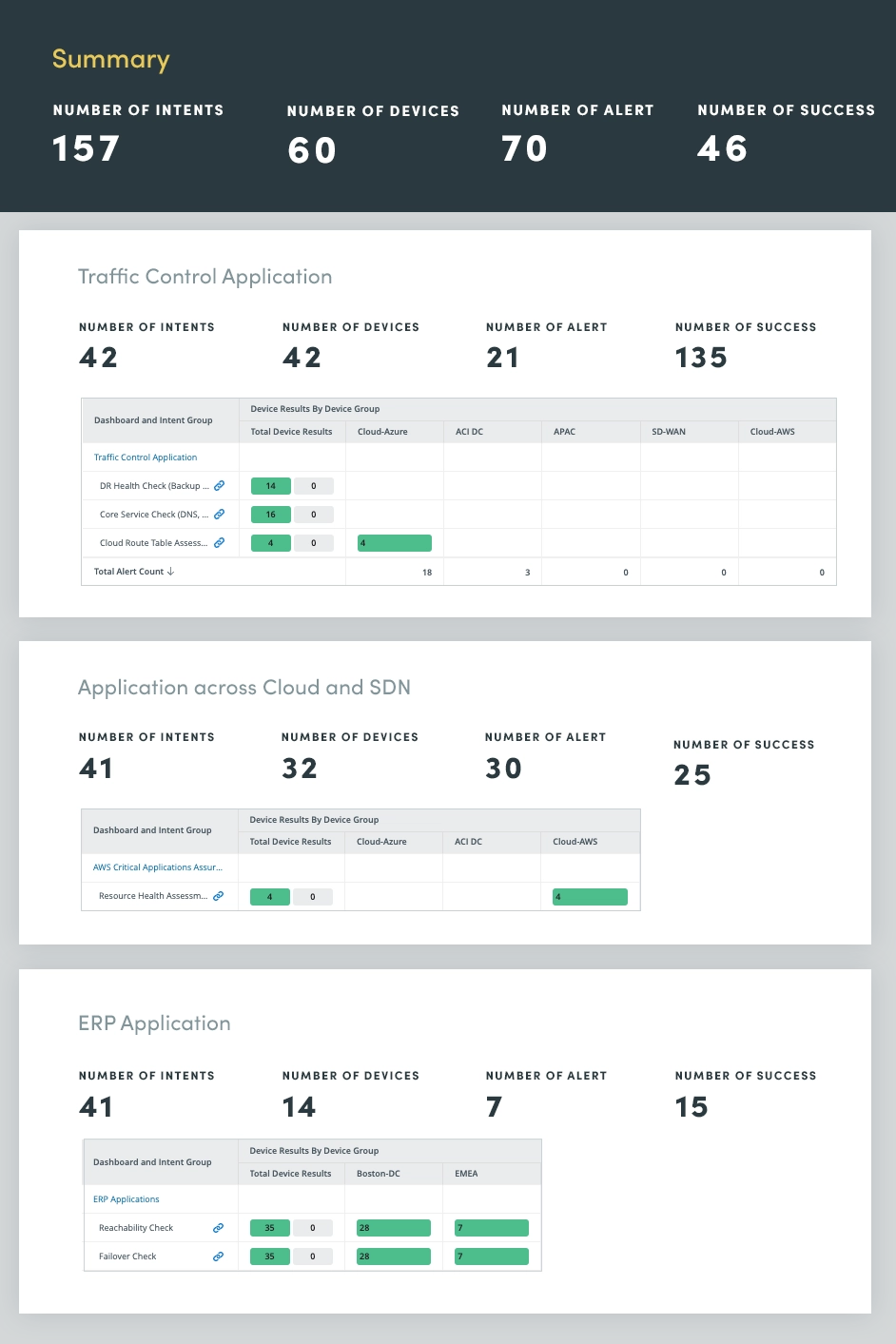
4. Kritische Anwendungsbewertung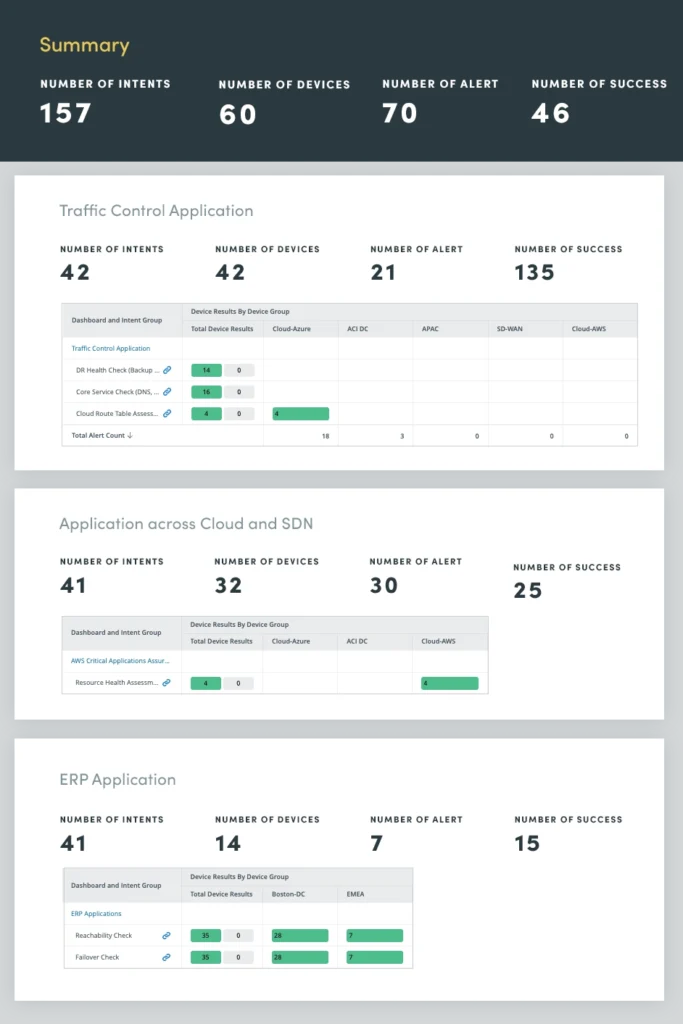
Durch die kontinuierliche Überwachung und Bewertung des Zustands geschäftskritischer Anwendungen können Sie potenzielle Probleme erkennen und beheben, bevor sie sich auf Benutzer auswirken oder Geschäftsprozesse stören. Dieser proaktive Ansatz trägt dazu bei, kostspielige Ausfälle zu verhindern, die Anwendungsleistung zu optimieren und die Gesamtsystemzuverlässigkeit zu verbessern.
Die Bewertung des Anwendungszustands umfasst eine umfassende Bewertung verschiedener Anwendungsmetriken und -komponenten, einschließlich CPU- und Speicherkapazität, QoS-Einbrüche, kritische Schnittstellennutzung und Aufgaben wie Protokollanalyse und Ereignisüberwachung, um potenzielle Anwendungsprobleme proaktiv zu identifizieren und zu beheben.
Durch die kontinuierliche Bewertung dieser kritischen Anwendungsmetriken können Sie wertvolle Einblicke in den Anwendungszustand gewinnen und so die Leistung optimieren, Ausfälle verhindern und ein positives Benutzererlebnis aufrechterhalten.
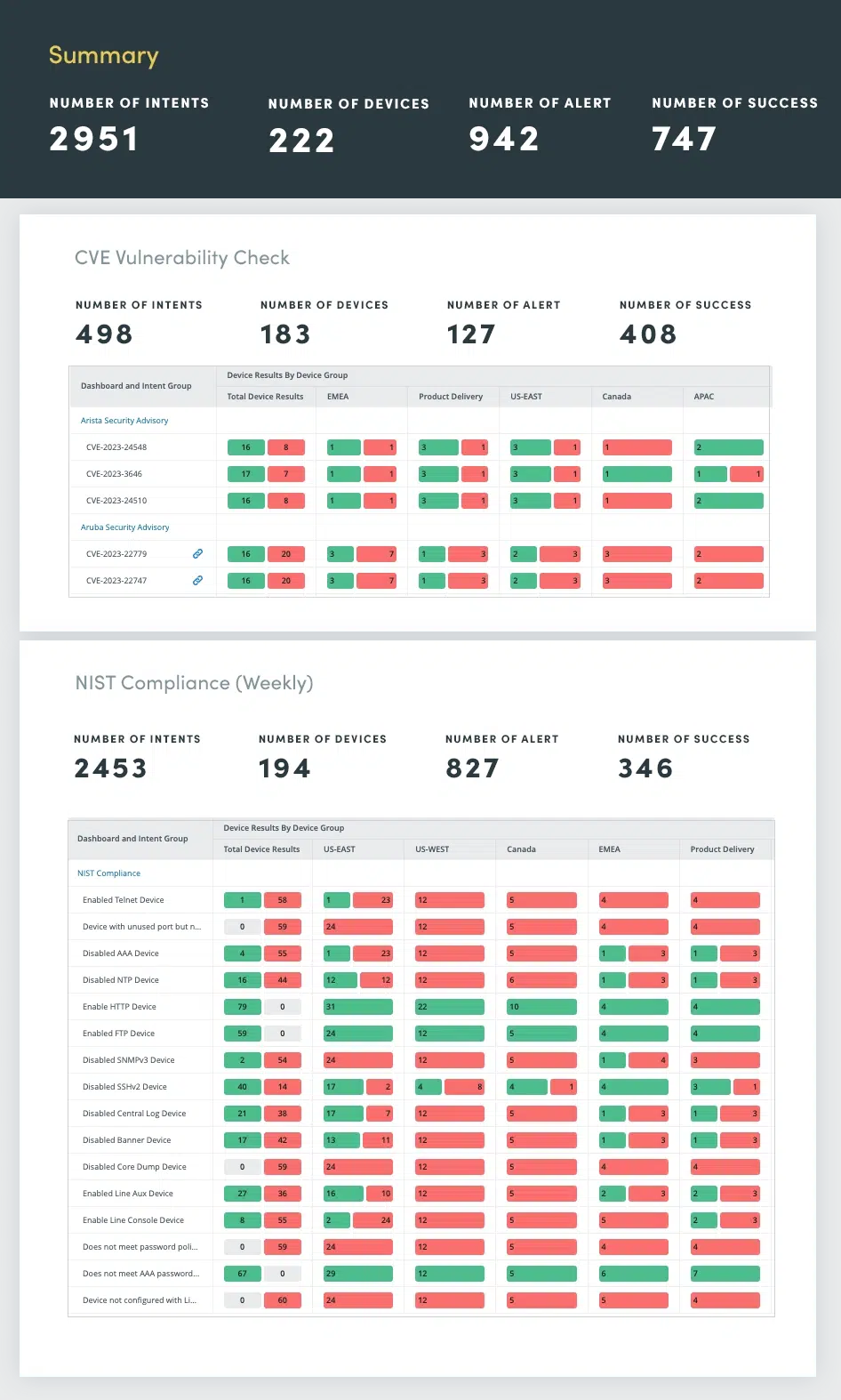
5. Sicherheitsbewertung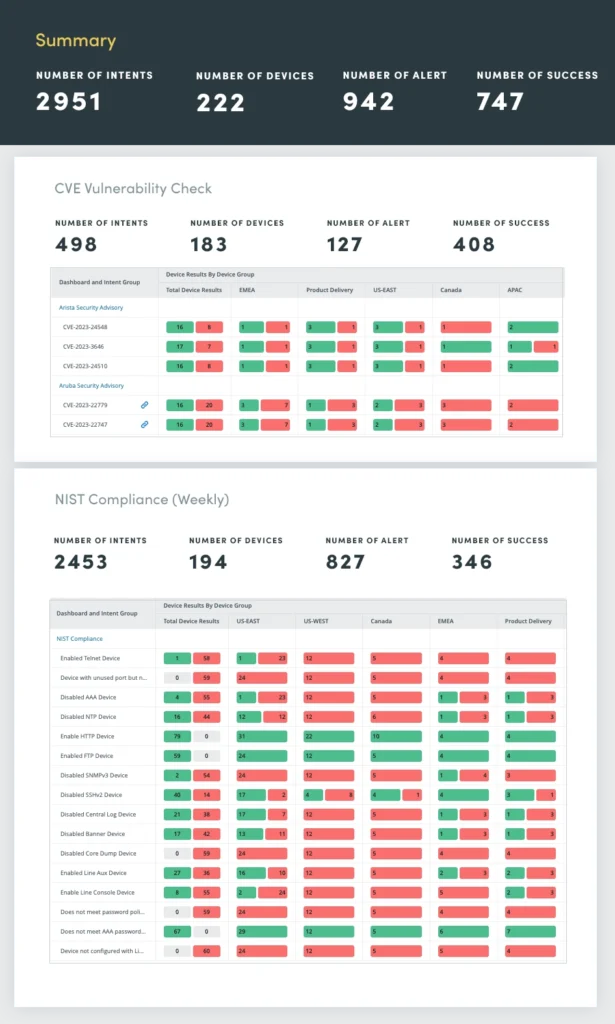
Stellen Sie sicher, dass Ihr Netzwerk gemäß den Vorgaben des National Institute of Standards and Technology (NIST) und den CVE-Bulletins nicht gefährdet ist. Von der Sicherheitskonformität bis hin zu den Empfehlungen des Anbieters: Bewerten Sie alle Schwachstellen und beheben Sie sie, bevor Probleme auftreten. Regelmäßige Netzwerksicherheitsbewertungen sind unerlässlich, um Schwachstellen zu identifizieren und zu beheben, die vertrauliche Daten gefährden, den Betrieb stören oder den Ruf eines Unternehmens schädigen könnten.
Netzwerksicherheitsbewertungen umfassen eine umfassende Bewertung verschiedener Sicherheitsaspekte, darunter:
- Einhaltung der Standards von NIST und der North American Electric Reliability Corporation (NERC)
- Schwachstellenerkennung mithilfe des CVE-Katalogs (Common Vulnerabilities and Exposures).
- Fehlkonfigurationen, die zu Sicherheitslücken führen können, wie z. B. schwache Passwörter, unsichere Protokolle und unbefugte Zugriffsberechtigungen
- Intrusion Detection/Prevention (IDS/IPS): Analysieren Sie IDS/IPS-Protokolle
- Analyse des Netzwerkverkehrs: Überwachen Sie den Netzwerkverkehr, um Anomalien zu erkennen, die auf verdächtige Aktivitäten oder Netzwerkangriffe hinweisen könnten
Durch die Automatisierung dieser Sicherheitsbewertungen können Sie die Netzwerklage kontinuierlich überwachen, Schwachstellen proaktiv identifizieren und beheben und eine robuste Verteidigung gegen sich entwickelnde Cyberbedrohungen aufrechterhalten.
6. Ökobilanz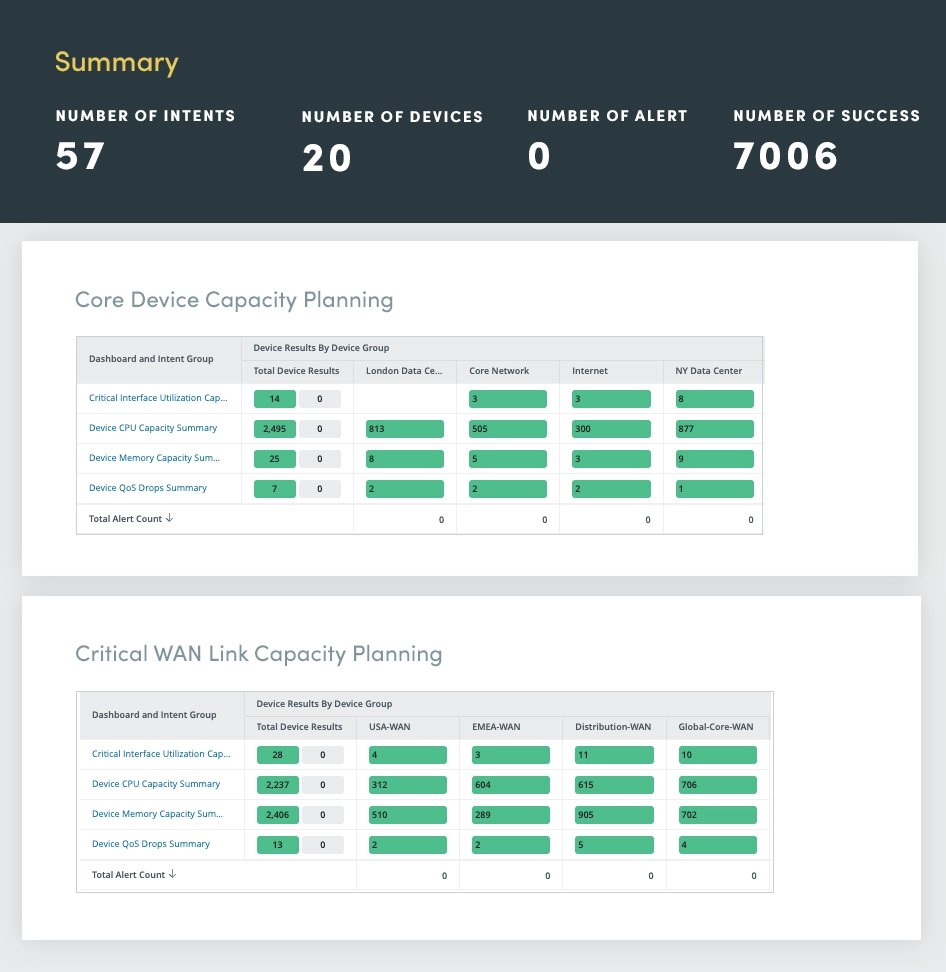
Eine umfassende Lebenszyklusanalyse kann Ihnen helfen, über den Lebenszyklusstatus Ihrer Netzwerkhardware informiert zu bleiben und zeitnahe Upgrades und Ersatzentscheidungen sicherzustellen.
Durch die Nutzung automatisierter API-Aufrufe an Hardwareanbieter wie Cisco erhalten Sie Echtzeitinformationen zu:
- End-of-Life-Status (EOL).
- Wartungsstatus:
- Servicevertragsstatus
- Garantiehinweise
- Treffen Sie fundierte Entscheidungen zum Hardware-Lebenszyklusmanagement und optimieren Sie Ihr Netzwerk im Hinblick auf Leistung, Sicherheit und Kosteneffizienz.
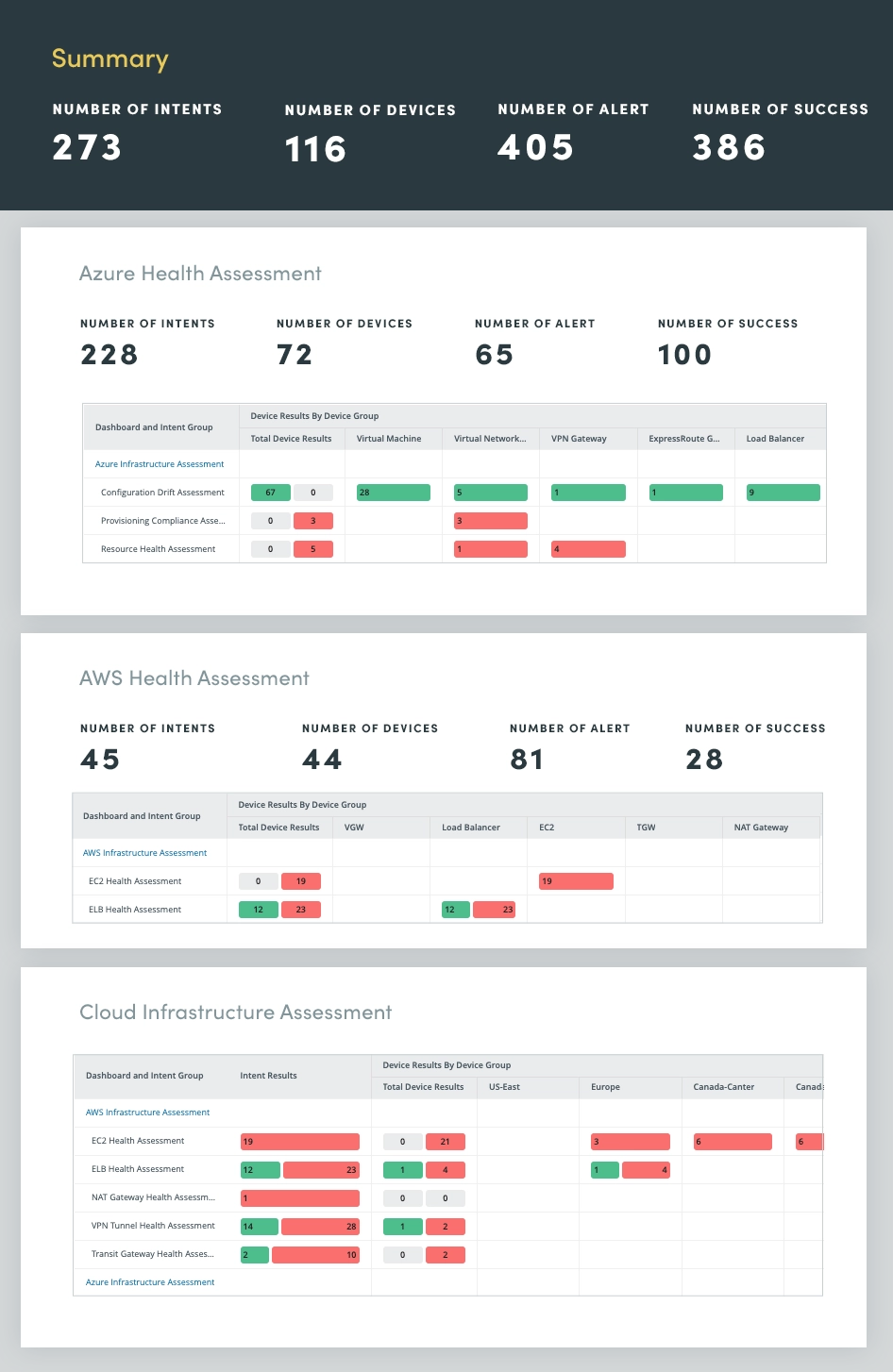
7. Bewertung des Hybrid-Cloud-Netzwerks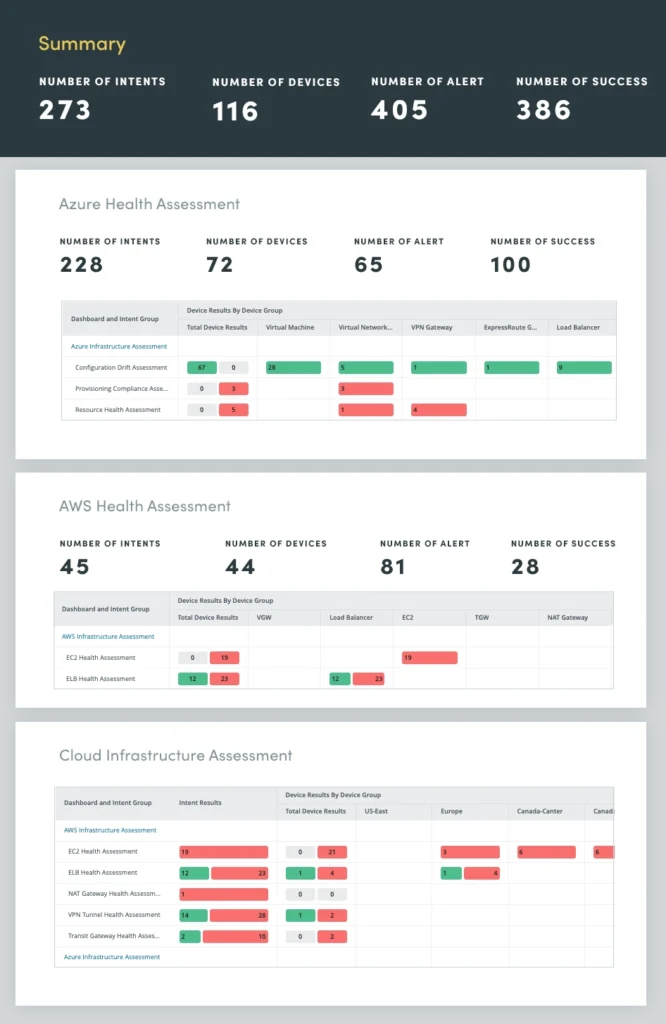
Durch die Automatisierung der Hybrid-Cloud-Netzwerkbewertung können Sie Ihre Cloud-Netzwerke bei mehreren Cloud-Anbietern, einschließlich Microsoft Azure, Amazon AWS und Google Cloud, kontinuierlich überwachen und bewerten, um Einblicke in Folgendes zu erhalten:
- Auslastung der Netzwerkressourcen
- Network Connectivity
- Zustand der virtuellen Appliance
- Cloudspezifische Metriken
Durch die kontinuierliche Bewertung des Hybrid-Cloud-Netzwerks können Sie potenzielle Probleme proaktiv identifizieren und beheben, die Leistung optimieren und eine sichere und belastbare Cloud-Infrastruktur aufrechterhalten.
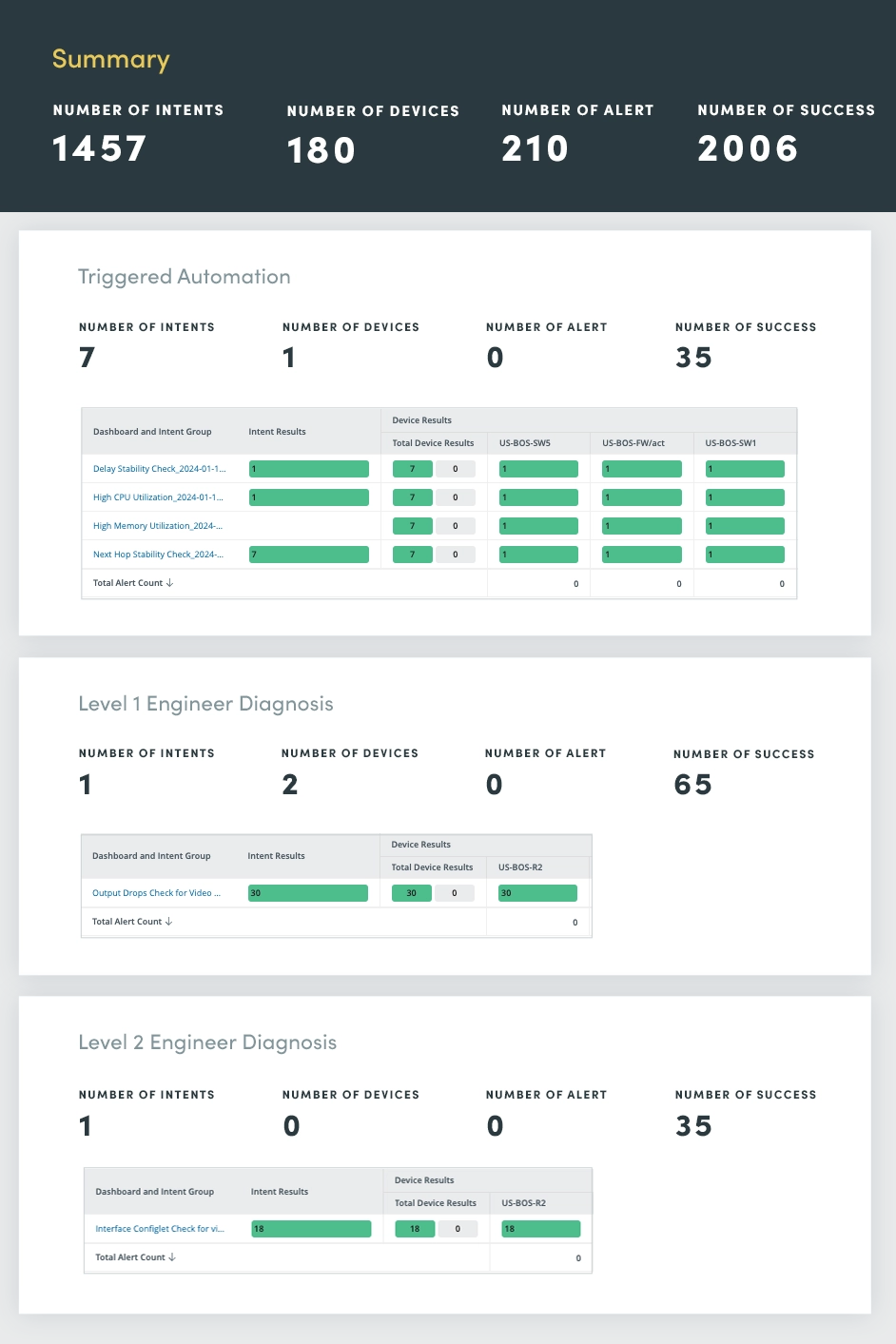
8. Ausgelöste Automatisierung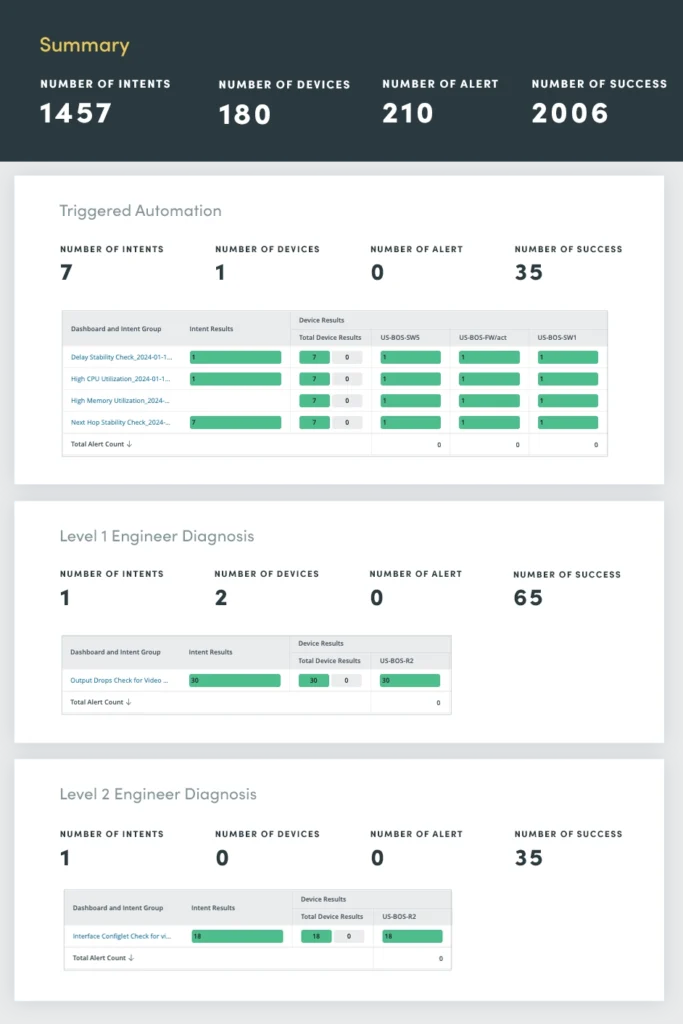
Das Triggered Automation Assessment dient als zentrale Drehscheibe für die Überwachung und Reaktion auf Netzwerkvorfälle in Echtzeit. Durch die Nutzung der Automatisierung können Sie Vorfallmanagementprozesse optimieren und so eine schnelle Diagnose, Priorisierung und Lösung ermöglichen.
Beim Empfang einer eingehenden Vorfallbenachrichtigung über die API wendet das ausgelöste Automatisierungs-Dashboard intelligente Autodiagnosefunktionen an:
- Automatisches Schließen tTicket: Wenn der Vorfall als Rauschen identifiziert wird, wird das Ticket automatisch geschlossen, wodurch die Arbeitsbelastung der Netzwerktechniker reduziert und unnötige Eskalationen vermieden werden.
- Automatisches Öffnen tTicket: Wenn ein Netzwerkproblem festgestellt wird, öffnen Sie automatisch ein Ticket und stellen Sie sicher, dass der Vorfall umgehend behoben und dokumentiert wird.
- Automatische Priorisierung tTicket: Wenn ein schwerwiegendes Problem gefunden wird, weisen Sie dem Ticket automatisch eine hohe Priorität zu. So werden die Netzwerktechniker auf die Dringlichkeit der Situation aufmerksam gemacht und können schnell eingreifen.
Durch die Automatisierung dieser Aufgaben zur Verwaltung kritischer Vorfälle werden die Reaktionszeiten erheblich verkürzt, Ausfallzeiten minimiert und die allgemeine Ausfallsicherheit des Netzwerks verbessert.
9. Bewertung vergangener Ausfälle
Nach einem Ausfall ist es wichtig zu prüfen, ob ähnliche Probleme auch an anderen Stellen im Netzwerk bestehen. Überlegen Sie bei jedem bekannten Problem, ob es an einem anderen Ort oder unter anderen Bedingungen erneut auftreten könnte. Eine problembasierte Bewertung – umfassend angewendet und kontinuierlich überwacht – hilft, diese Risiken aufzudecken. Um zukünftige Ausfallzeiten tatsächlich zu reduzieren, müssen Teams über die Ursachenanalyse hinausgehen. Sie müssen proaktiv nach Mustern suchen, Schwachstellen identifizieren und diese Erkenntnisse nutzen, um das Netzwerk gegen wiederholte Ausfälle zu wappnen.
Durch die Analyse vergangener Ausfälle können Unternehmen:
- Identifizieren Sie wiederkehrende Muster und zugrunde liegende Faktoren, die zu Netzwerkausfällen beitragen, und ermöglichen Sie so gezielte Abhilfestrategien.
- Entdecken Sie versteckte Schwachstellen oder Fehlkonfigurationen, die bei ersten Bewertungen möglicherweise übersehen wurden, und verhindern Sie so zukünftige Ausfälle.
- Implementieren Sie vorbeugende Maßnahmen und stärken Sie die Ausfallsicherheit der Netzwerkinfrastruktur, um ein erneutes Auftreten zu reduzieren.
Indem Sie frühere Probleme proaktiv angehen und daraus lernen, können Sie die Widerstandsfähigkeit Ihres Netzwerks erheblich verbessern und Ihr Ausfallrisiko minimieren.
10. Kapazitätsbewertung
Die kontinuierliche Kapazitätsbewertung hilft, Über- und Unterauslastung durch die Analyse von Verkehrsmustern, Ressourcenverbrauch und Leistungskennzahlen in Echtzeit zu vermeiden. Dieser proaktive Ansatz bietet Transparenz, um die Nachfrage vorherzusehen, die Netzwerkleistung zu optimieren und einen reibungslosen Geschäftsbetrieb aufrechtzuerhalten.
Ermöglichen Sie proaktive Planungs- und Skalierungsstrategien, indem Sie zukünftige Kapazitätsanforderungen vorhersehen, um kostspielige reaktive Maßnahmen zu vermeiden, indem Sie diese Schlüsselkennzahlen überwachen:
- Bandbreite uTilisierung: Überwacht den Prozentsatz der genutzten verfügbaren Bandbreite und zeigt potenzielle Engpässe an.
- Gerät rQuelle uTilisierung: Verfolgt die Auslastung von CPU, Speicher und anderen Ressourcen auf Netzwerkgeräten und identifiziert potenzielle Engpässe.
- Anwendung performance mMetriken: Bewerten Sie die Leistung kritischer Anwendungen unter unterschiedlichen Netzwerkbedingungen und heben Sie potenzielle Kapazitätsbeschränkungen hervor.
Treffen Sie fundiertere Entscheidungen, um die Leistung zu optimieren und Skalierbarkeit sicherzustellen.
Verhindern Sie Netzwerkausfälle mit NetBrain
Die No-Code-Netzwerkautomatisierung verwandelt die traditionelle Netzwerkbewertung von einer veralteten Audit-Aufgabe in ein strategisches Echtzeit-Betriebstool, das Betriebsteams täglich unterstützt. Bewerten Sie die Netzwerkleistung proaktiv mit automatisierten Diagnosen und Erkenntnissen. So können Sie potenzielle Probleme erkennen und beheben, bevor sie den Geschäftsbetrieb beeinträchtigen.
Sind Sie bereit, mit dem Aufbau eines widerstandsfähigeren Netzwerks zu beginnen? Planen Sie noch heute eine Demo zu erkunden, wie NetBrain kann Ihrem Team helfen, Ausfälle zu verhindern.
 by
by